【pandas】データフレームをCSVやExcelなどで出力する方法
当ページのリンクには広告が含まれています。

pandasではデータフレームとして読み込んだデータを複数の形式で出力することができます。
今回は、CSVやExcelなどで出力する方法をご紹介いたします。
この記事におすすめの人
- pandasを使ってcsvやExcel出力をしたい
- Excelファイルに、複数のシートに分けて出力したい
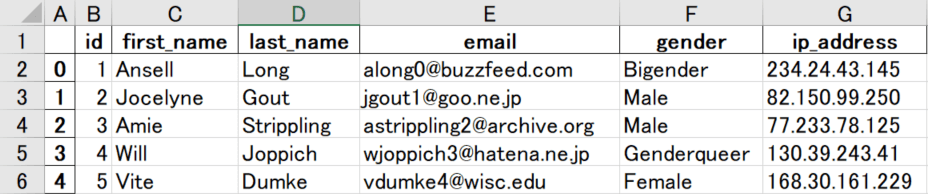
サンプルデータとして、下記のようなファイルを用意しました。
import pandas as pd
df = pd.read_csv('sample.csv')
df.head()スクロールできます
| id | first_name | last_name | gender | ip_address | |
|---|---|---|---|---|---|
| 1 | Ansell | Long | along0@buzzfeed.com | Bigender | 234.24.43.145 |
| 2 | Jocelyne | Gout | jgout1@goo.ne.jp | Male | 82.150.99.250 |
| 3 | Amie | Strippling | astrippling2@archive.org | Male | 77.233.78.125 |
| 4 | Will | Joppich | wjoppich3@hatena.ne.jp | Genderqueer | 130.39.243.41 |
| 5 | Vite | Dumke | vdumke4@wisc.edu | Female | 168.30.161.229 |
あわせて読みたい


【データの前処理・可視化】Pythonでのデータ処理まとめ
pythonでのデータ処理についてまとめました。 サンプルコード類 pandasを使った前処理 よく使う基本的な使い方 pythonのライブラリ「pandas」を使って、様々なcsvやExce…
目次
CSV—to_csv()
df.to_csv('export_data.csv')データフレーム.to_csv(“ファイル名”)で出力できます。

主な引数
インデックスの表示・非表示
インデックスが不要な場合はindex=Falseとします。
df.to_csv('export_data.csv', index=False)ヘッダーの表示・非表示
ヘッダーも同様にheader=Falseとできます。
Excel—to_excel()
df.to_excel("export_data.xlsx")データフレーム.to_excel(“ファイル名”)で出力できます。
主な引数
インデックス・ヘッダーの表示・非表示
to_csv()と同様にindex=Falseやheader=Falseで非表示にできます。
df.to_excel("export_data.xlsx", index=False, header=False)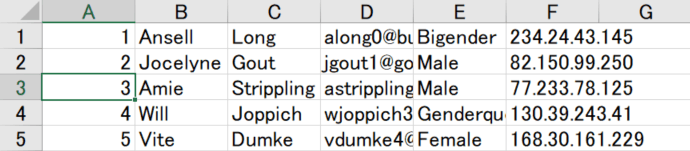
シート名の変更
シート名を変更する場合はsheet_name="シートの名前"とします。
複数シートへの出力
複数シートへ出力する場合には、pd.ExcelWriter()オブジェクトを作成し、それぞれのシートに書き込みます。
with pd.ExcelWriter("export_data.xlsx") as EW:
df1.to_excel(EW, index=False, sheet_name="df1")
df2.to_excel(EW, index=False, sheet_name="df2")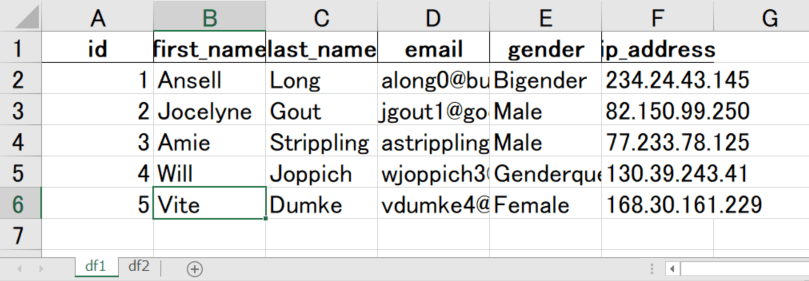
この機能はとても便利ですね。
 ケン
ケンどうしても会社ではExcelでちょうだいと言われる機会が多いので重宝しています。
辞書型—to_dict()
df.to_dict()辞書型で出力したい場合にはto_dict()を用います。
{'id': {0: 1, 1: 2, 2: 3},
'first_name': {0: 'Ansell', 1: 'Jocelyne', 2: 'Amie'},
'last_name': {0: 'Long', 1: 'Gout', 2: 'Strippling'},
'email': {0: 'along0@buzzfeed.com',
1: 'jgout1@goo.ne.jp',
2: 'astrippling2@archive.org'},
'gender': {0: 'Bigender', 1: 'Male', 2: 'Male'},
'ip_address': {0: '234.24.43.145', 1: '82.150.99.250', 2: '77.233.78.125'}}引数に何も指定しない場合はカラムが辞書のキーとなります。
辞書の種類は引数orientで変えられます。
主な引数
orient = “辞書の型の指定”
引数orientには引数の値によって辞書のタイプを変更できます。
ドキュメントに記載されている内容から、自分が使いたいものを選択ください。
- 'dict' (default) : dict like {column -> {index -> value}}
- 'list' : dict like {column -> [values]}
- 'series' : dict like {column -> Series(values)}
- 'split' : dict like
{'index' -> [index], 'columns' -> [columns], 'data' -> [values]}
- 'records' : list like
[{column -> value}, ... , {column -> value}]
- 'index' : dict like {index -> {column -> value}}
例えば、orient = “index”だと
df_dict = df.to_dict(orient="index")
df_dict{0: {'id': 1,
'first_name': 'Ansell',
'last_name': 'Long',
'email': 'along0@buzzfeed.com',
'gender': 'Bigender',
'ip_address': '234.24.43.145'},
1: {'id': 2,
'first_name': 'Jocelyne',
'last_name': 'Gout',
'email': 'jgout1@goo.ne.jp',
'gender': 'Male',
'ip_address': '82.150.99.250'},
2: {'id': 3,
'first_name': 'Amie',
'last_name': 'Strippling',
'email': 'astrippling2@archive.org',
'gender': 'Male',
'ip_address': '77.233.78.125'}}上記のようになります。
参考
- pandas.DataFrame.to_csv — pandas 1.2.2 documentation
- pandas.DataFrame.to_excel — pandas 1.2.2 documentation
- pandas.DataFrame.to_dict — pandas 1.2.2 documentation
機械学習・データ処理を学ぶのにおすすめの教材
じっくり書籍で学習するなら!




¥2,090 (2022/02/20 08:45時点 | Amazon調べ)
コメント