【pandas】基本的な使い方【読み込み・表示・結合】

Pythonで機械学習やデータ分析で活用されるライブラリとして「Pandas」が有名です。
機械学習の分野だけではなく、日常的に行っているExcelやCSVでの処理を自動化できます。
今回は「読み込み・表示・結合」について使い方をご紹介します。
pythonが使える環境構築が必要です!環境構築なら「Anaconda」がおススメです!

Pandasのインストール
import pandas as pdデータの読み込み
サンプルファイルとして、簡単なCSVファイルを作成しました。
# saple.csv
no name age
0 1 taro 25
1 2 ken 28
2 3 akari 13
3 4 takeshi 56
4 5 jiro 75
5 6 satoru 33
6 7 haru 26
7 8 korosuke 14
8 9 meme 82
9 10 saori 46CSVファイルの読み込み—read_csv( )
CSVファイルの読み込みはread_csv( )で読み込めます。
カンマ区切りではなく、タブ区切りの場合は引数にsep='\t'で区切り文字を指定できます。
df = pd.read_csv('sample.csv')
df = pd.read_csv('sample.tsv, sep='\t')
エンコードの明示
Excelから作成したCSVファイルは直接読み込むとエラーが発生します。
文字コードがUTF-8ではないからです。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 0: invalid start byteファイルをUTF-8にするか読み込む際に、引数にencoding='shift_jis'を指定します。
data = pd.read_csv('sample.csv', encoding='shift_jis')ヘッダーが無い場合
ヘッダーが無い場合には、1行目の値がカラムとして認識されます。
認識を避ける場合には、header=Noneとします。
カラム名をつける場合にはcolumns=('No', '名前', '年齢')と指定できます。
df = pd.read_csv('sample.csv', header=None)
df = pd.read_csv('sample.csv', columns=('No', '名前', '年齢'))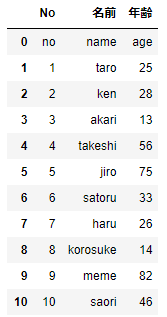
カラム名が変わりました。
データの表示
最初の〇〇行表示—df.head( )
データを読み込んだ後は、どのようなデータ構造なのか確認してみましょう。head( )で最初の5行が読み込めます。
df.head()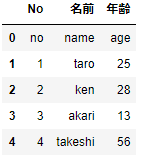
引数に数字を入力すれば、任意の行数を取得できます。
行数の確認—len(df)
データフレームにlen(df)で確認できます。
>>> len(df)
11行・列の確認—df.shape
行・列の数値を確認する場合には、df.shapeを使います。
>>> df.shape
(11, 3)タプルで値が返ってきます。
カラム名の確認—df.columns
カラム名を確認する場合には、df.columnsを用います。
>>> df.columns
Index(['No', '名前', '年齢'], dtype='object')欠損値の確認—df.info()
欠損値の確認をする場合にはdf.info()を用います。
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 no 10 non-null int64
1 name 10 non-null object
2 age 10 non-null int64
dtypes: int64(2), object(1)
memory usage: 368.0+ bytes各カラムに対して、non-nullの数や型が確認できます。
統計量の確認—df.describe( )
基本的な統計量を取得できます。
- 件数(count)
- 平均(mean)
- 標準偏差(std)
- 最小値・最大値(min ・ max)
- 中央値など(50%)
などが取得できます。
数値の傾向を掴めるので、よく使われます。
>>> df.describe()
Unnamed: 0 points price
count 129971.000000 129971.000000 120975.000000
mean 64985.000000 88.447138 35.363389
std 37519.540256 3.039730 41.022218
min 0.000000 80.000000 4.000000
25% 32492.500000 86.000000 17.000000
50% 64985.000000 88.000000 25.000000
75% 97477.500000 91.000000 42.000000
max 129970.000000 100.000000 3300.000000数値型の変数以外も表示させる場合にはinclude='all'とします。
>>> df.describe(include='all')
no name age
count 10.00000 10 10.000000
unique NaN 10 NaN
top NaN satoru NaN
freq NaN 1 NaN
mean 5.50000 NaN 39.800000
std 3.02765 NaN 24.266117
min 1.00000 NaN 13.000000
25% 3.25000 NaN 25.250000
50% 5.50000 NaN 30.500000
75% 7.75000 NaN 53.500000
max 10.00000 NaN 82.000000分布量の確認—df.value_counts()
データの分布量を確認する場合には、df.value_counts()が便利です。
>>> df.value_counts()
no name age
10 saori 46 1
9 meme 82 1
8 korosuke 14 1
7 haru 26 1
6 satoru 33 1
5 jiro 75 1
4 takeshi 56 1
3 akari 13 1
2 ken 28 1
1 taro 25 1出現個数が表示されます。
また、Seriesとして特定カラムのみの抽出も可能です。
>>> df2 = pd.read_csv('sample2.csv', encoding='shift_jis')
>>> df2.head(5)
No 性別 都道府県
0 1 male 東京都
1 2 male 神奈川県
2 3 female 北海道
3 4 male 静岡県
4 5 male 東京都
>>> df2['性別'].value_counts()
male 6
female 4
Name: 性別, dtype: int64データの結合
縦に結合(行の追加)—df.concat()
基本的に同じ構造のデータを入れます。例えば、
- 毎月の売り上げデータ
- アクセスログ
など同じデータ構造で期間で複数ファイルに分割されているものを結合したいときによく使われます。
df = pd.concat([df1, df2], ignore=True)引数による指定で列方向での結合も可能ですが、混乱するのでまずは「行追加」だけ押さえます。
横に結合(列の追加)—df.merge()
merge( )は横方向に結合します。キーとなる列を指定して、列を追加します。
データを追加して結合してみます。
SQLでの外部結合・内部結合のような使い方ができます。

# sample2.csv
No 性別 都道府県
1 male 東京都
2 male 神奈川県
3 female 北海道
4 male 静岡県
5 male 東京都
6 male 岩手県
7 female 新潟県
8 male 神奈川県
9 female 青森県
10 female 熊本県dfとdf2を「No」をキーとして結合します。
>>> df_new = pd.merge(df, df2, on='no', how='left')
>>> df_new
no name age sex pref
1 taro 25 male 東京都
2 ken 28 male 神奈川県
3 akari 13 female 北海道
4 takeshi 56 male 静岡県
5 jiro 75 male 東京都
6 satoru 33 male 岩手県
7 haru 26 female 新潟県
8 korosuke 14 male 神奈川県
9 meme 82 female 青森県
10 saori 46 female 熊本県結合されました。
参考
機械学習・データ処理を学ぶのにおすすめの教材
じっくり書籍で学習するなら!




コメント