【pandas】外れ値を確認・除去する方法【df.quantile()】

データ分析や機械学習では、精度を上げるために外れ値などを除去し、適切なデータセットにすることが重要です。
今回は、外れ値を確認し除去する方法をご紹介いたします。
- 記述統計量やグラフから外れ値の確認方法
- 任意の位数・値から外れ値を除去する方法

ライブラリのインポート
まずは必要なライブラリをインポートします。
import warnings
warnings.simplefilter('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()データの準備
データはsklearnのload_dataset()からボストンの住宅価格データセットを用います。
from sklearn.datasets import load_boston
boston = load_boston()
boston_df = pd.DataFrame(data=boston.data,columns=boston.feature_names)
boston_df['target'] = boston.target
boston_df.head()| CRIM | ZN | INDUS | CHAS | NOX | ・・・ | AGE | DIS | RAD | TAX | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | ・・・ | 65.2 | 4.0900 | 1.0 | 296.0 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | ・・・ | 78.9 | 4.9671 | 2.0 | 242.0 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | ・・・ | 61.1 | 4.9671 | 2.0 | 242.0 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | ・・・ | 45.8 | 6.0622 | 3.0 | 222.0 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | ・・・ | 54.2 | 6.0622 | 3.0 | 222.0 | 36.2 |
外れ値の把握
外れ値を考える際には「記述統計量」や「グラフ」からデータがどのような分布になっているかを確認します。
今回は町ごとの「一人当たりの犯罪率」を表している"CRIM"を見ていきます。
記述統計量の確認
記述統計量を確認する場合にはdf.describe()関数を用います。
boston_df[['CRIM','target']].describe()| CRIM | target | |
|---|---|---|
| count | 506.000000 | 506.000000 |
| mean | 3.613524 | 22.532806 |
| std | 8.601545 | 9.197104 |
| min | 0.006320 | 5.000000 |
| 25% | 0.082045 | 17.025000 |
| 50% | 0.256510 | 21.200000 |
| 75% | 3.677083 | 25.000000 |
| max | 88.976200 | 50.000000 |
CRIMの最大値を確認すると、犯罪率が88%と異常な値になっています。また、ほとんどの値は3.7%以下であることが分かりました。
機械学習・データ分析において、あまり現実的ではない数値はノイズとなります。
次は散布図で可視化してみましょう。
グラフでの可視化
データの分布がどのようになっているかグラフで確認してみます。

ヒストグラム
sns.distplot(boston_df.CRIM)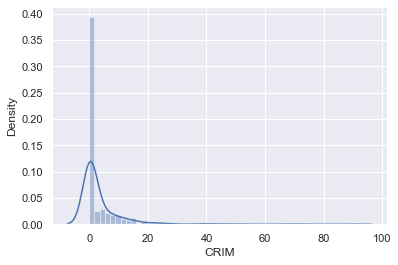
箱ひげ図
sns.boxplot(data=boston_df.CRIM)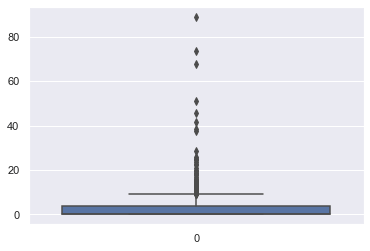
散布図
sns.scatterplot(x="CRIM", y="target", data=boston_df)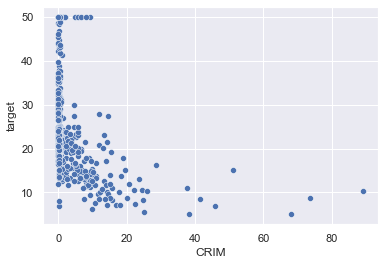
各種グラフで見られたように以下のことが分かりました。
- 全体的な割合では犯罪発生率は20%以下になっている
- ほぼ10%以下である
- 犯罪発生率が低い程、target(価格)は高くなる負の相関が見られる
これを元に外れ値を除去していきます。
外れ値の除去
外れ値を除去する方法として、主に2種類の方法があります。
- 分位数を指定する
- 任意の値を指定する
今回は分位数を指定する方法を見ていきます。
分位数を指定する—df.quantile()
データフレームの任意の分位数での値を出すにはdf.quantile()関数を用います。
引数として0~1の値を与えて、任意の分位数での値を取得できます。
例えば、中央値の第2四分位数の50%での値を求める場合には0.5とします。
>>> q_50 = boston_df.CRIM.quantile(0.5)
>>> q_50
0.256510.25651が中央値となります。念のため、もう一度記述統計量を確認してみましょう。
boston_df[['CRIM','target']].describe()| CRIM | target | |
|---|---|---|
| count | 506.000000 | 506.000000 |
| mean | 3.613524 | 22.532806 |
| std | 8.601545 | 9.197104 |
| min | 0.006320 | 5.000000 |
| 25% | 0.082045 | 17.025000 |
| 50% | 0.256510 | 21.200000 |
| 75% | 3.677083 | 25.000000 |
| max | 88.976200 | 50.000000 |
きちんと取得できていますね。
今回は分位数95%の値を取得して、外れ値を除去していきます。
>>> q = boston_df.CRIM.quantile(0.95)
>>> q
15.7891595%の分位数の値が約15.7となりました。
この値を元に、df.query()関数を使って絞り込みます。

new_boston_df = boston_df.query('CRIM < @q')犯罪発生率が95%の位数よりも値が小さいデータが抽出できました。
データの確認
外れ値が除去できているか、再度記述統計量を確認してみます。
new_boston_df[['CRIM', 'target']].describe()| CRIM | target | |
|---|---|---|
| count | 480.000000 | 480.000000 |
| mean | 2.092157 | 23.203542 |
| std | 3.648801 | 8.932629 |
| min | 0.006320 | 6.300000 |
| 25% | 0.078832 | 17.800000 |
| 50% | 0.222000 | 21.700000 |
| 75% | 2.256870 | 26.250000 |
| max | 15.575700 | 50.000000 |
データ数が506件から480件へ減少し、犯罪発生率の最大値が15.57になりました。
うまく抽出できていますね。散布図でも見ていきましょう。
sns.scatterplot(x="CRIM", y="target", data=new_boston_df)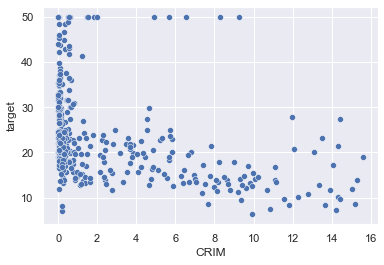
外れ値が除去されていますね!
機械学習・データ処理を学ぶのにおすすめの教材
じっくり書籍で学習するなら!




コメント