【pandas】groupbyでデータフレームをまとめる方法
当ページのリンクには広告が含まれています。

pandasのgroupbyは同じ値を持つデータをまとめることができます。
データをまとめる用途以外にもグループごとに処理を行ったり、グラフ作成など重要な関数となりますのでご紹介いたします。
あわせて読みたい


【データの前処理・可視化】Pythonでのデータ処理まとめ
pythonでのデータ処理についてまとめました。 サンプルコード類 pandasを使った前処理 よく使う基本的な使い方 pythonのライブラリ「pandas」を使って、様々なcsvやExce…
目次
サンプルデータの作成
import numpy as np
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
%matplotlib inline必要なライブラリをインポートし
df = DataFrame({'C1':["A","B","B","C","C"],
'C2':["TKO","HKD","OSK","CBA","TKO"],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df| C1 | C2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | A | TKO | 0.968959 | 0.769093 |
| 1 | B | HKD | 0.786134 | 2.327999 |
| 2 | B | OSK | -0.159909 | -0.793272 |
| 3 | C | CBA | 0.536466 | 0.469165 |
| 4 | C | TKO | 1.538217 | 0.481457 |
このようなデータフレームを作成しました。
groupbyの使い方
基本
df.groupby()で引数に任意の値でグルーピングできます。
>>> g1 = df.groupby("C1")
>>> g1
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001F27A916730>groupbyでの返り値はgroupbyオブジェクトとなり、合計や平均など関数処理を与えることで値が返ってきます。
g1.sum()| data1 | data2 | |
|---|---|---|
| C1 | ||
| A | -1.674337 | -0.201740 |
| B | 1.099597 | 1.265032 |
| C | -0.358653 | -0.549444 |
C1カラムの値である「A・B・C」それぞれの合計値が返ってきました。
グラフで可視化してみましょう。df.plot()で作成できます。
あわせて読みたい

【matplotlib】データフレームのグラフ作成方法と主な種類
matplotlibにはx軸・y軸に値を渡してやる方法もありますが、今回はpandasのデータフレームからグラフ生成の方法をご紹介します。 この記事で分かること データフレーム…
g1.sum().plot(kind="barh")
plt.legend(loc="lower right")
複数のグループでまとめる
1つのカラムではなく、複数グループでグルーピングする場合には、リストで渡します。
g2 = df.groupby(["C1","C2"])
g2.sum()| data1 | data2 | ||
|---|---|---|---|
| C1 | C2 | ||
| A | TKO | -1.674337 | -0.201740 |
| B | HKD | -0.048393 | 1.223421 |
| OSK | 1.147990 | 0.041612 | |
| C | CBA | -0.101004 | -0.089792 |
| TKO | -0.257649 | -0.459652 |
C1、C2の2階層でグルーピングされています。同様にグラフを作ってみましょう。
g2.sum().plot(kind="barh")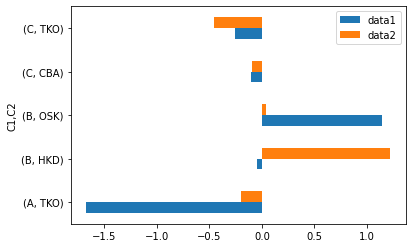
ちゃんと反映されています。
表示するカラムの指定方法
特定のカラムのみ表示する場合には、df.groupby()[["カラム名"]]で指定します。
g3 = df.groupby(["C1","C2"])[['data1']]
g3.mean()| data1 | ||
|---|---|---|
| C1 | C2 | |
| A | TKO | -1.674337 |
| B | HKD | -0.048393 |
| OSK | 1.147990 | |
| C | CBA | -0.101004 |
| TKO | -0.257649 |
data1だけの表示になりました。
インデックスにしない場合
引数にas_index=Falseとします。
g4 = df.groupby(["C1","C2"], as_index=False)
g4.mean()| C1 | C2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | A | TKO | -1.674337 | -0.201740 |
| 1 | B | HKD | -0.048393 | 1.223421 |
| 2 | B | OSK | 1.147990 | 0.041612 |
| 3 | C | CBA | -0.101004 | -0.089792 |
| 4 | C | TKO | -0.257649 | -0.459652 |
インデックスがカラムではなく、数値となりました。
主な組込み関数
| 関数 | 説明 |
|---|---|
| mean() | 平均 |
| sum() | 合計 |
| size() | グループの大きさ |
| count() | グループのデータ個数 |
| std() | 標準偏差 |
| describe() | グループ内の統計量 |
| first() | グループ内の先頭 |
| last() | グループ内の最後 |
| min() | 最小値 |
| max() | 最大値 |
任意の処理を行うagg()
組み込み関数ではなく、任意の処理を行いたい場合にはagg()を使う。
基本
agg()の引数として、適用したい関数を指定する。
g5 = df.groupby(["C1","C2"]).agg(np.max)
g5| data1 | data2 | ||
|---|---|---|---|
| C1 | C2 | ||
| A | TKO | 0.968959 | 0.769093 |
| B | HKD | 0.786134 | 2.327999 |
| OSK | -0.159909 | -0.793272 | |
| C | CBA | 0.536466 | 0.469165 |
| TKO | 1.538217 | 0.481457 |
複数の関数の適用
複数の関数を適用したい場合にはリストで渡します。
g6 = df.groupby(["C1","C2"]).agg([np.max, np.min])
g6| data1 | data2 | ||||
|---|---|---|---|---|---|
| amax | amin | amax | amin | ||
| C1 | C2 | ||||
| A | TKO | 0.968959 | 0.968959 | 0.769093 | 0.769093 |
| B | HKD | 0.786134 | 0.786134 | 2.327999 | 2.327999 |
| OSK | -0.159909 | -0.159909 | -0.793272 | -0.793272 | |
| C | CBA | 0.536466 | 0.536466 | 0.469165 | 0.469165 |
| TKO | 1.538217 | 1.538217 | 0.481457 | 0.481457 | |
任意の関数
defで定義した関数やラムダ式も使えます。
def max_func(x):
return max(x)
g7 = df.groupby(["C1","C2"]).agg(max_func)
参考
pandas公式ドキュメント:pandas.DataFrame.groupby
機械学習・データ処理を学ぶのにおすすめの教材
じっくり書籍で学習するなら!




¥2,090 (2022/02/20 08:45時点 | Amazon調べ)
コメント